Script 1/2: retrieving data from dispatch (date, article number and place names)
This script allows you to apply a specific date as filter in order to reduce the amount of results. This is necessary because without a filter the SNL model is too heavy and besides memory errors while loading it the network is to complex to understand. The script uses a counter for articles and places combined with the article date to create unique IDs.
from bs4 import BeautifulSoup
import re
import os
newPathToFolder = "----path to target folder to save files----"
pathToFolder = "----path to source folder with dispatch xml files----"
listOfFiles = os.listdir(pathToFolder)
# function with one argument filter to define a specific date which will use values of the dispatch only if the date is true
def generate(filter):
placeNames = []
dicFreq = {}
resultsCSV = []
# for loop to access all files
for f in listOfFiles:
soup = BeautifulSoup (open(pathToFolder+f, "r", encoding="utf8"), features="html.parser")
# searches for list items of "date" and return maximum two elemens
issue_date = soup.find_all("date", limit=2)[1] # only returns the second match
issue_date = issue_date.get("value")
# searches for all tags with "div3" and stores it in variable "articles"
articles = soup.find_all("div3", type = True)
if issue_date.startswith(filter):
for a, item in enumerate(articles):
counter = str(a) + "-" + str(issue_date) # for loop that counts each article and combines it wit the date in the dispatch
places = item.find_all("placename", key = True) # continues to find all placenames with an attribute
article = "article-" + counter # variable that holds the issue date of the dispatch a string and an article counter
print(article)
for a, item in enumerate(places):
counter2 = str(a) + "-" + counter # counter2 will be the unique identifier ID for each row
place = item.get_text() # for loop to retrieve all placenames as value from the placename tag
key = item["key"].split(";") # variable that holds the tgn number
print(str(place))
for k in key:
key = [d for d in k if d.isdigit()] # for loop to clean tgn numbers digits only
tag_id = ''.join(key)
placeList = "\t".join([counter2,issue_date,article,place,tag_id]) # creating a variable that holds each result article, place, tag_id
placeNames.append(placeList) # appending the variable to a list
for i in placeNames: # creating a frequency with a for loop for all placenames
if i in dicFreq:
dicFreq[i] += 1
else:
dicFreq[i] = 1
for key, value in dicFreq.items(): # removes all placenames that are mention once only
if value < 2: # this will exclude items with frequency higher than 1 - we want unique rows
newVal = "%09d\t%s" % (value, key)
# newVal will looks like: `000005486 TAB Richmond`
resultsCSV.append(newVal)
resultsCSV = sorted(resultsCSV, reverse=True) # sorting the results variable
print(len(resultsCSV)) # will print out the number of items in the list
resultsToSave = "\n".join(resultsCSV) # joining the results line by line
# creates a new file in a target folder with name + article counter + name + issue_date + txt file
newfile = newPathToFolder + "placesFull_3.3.csv"
# creating a header for the final file
header = "freq\tid\tdate\tsource\ttarget\ttgn\n"
# opens the newfile and writes each article into a sperate file
with open(newfile, "w", encoding="utf8") as f8:
f8.write(header+"".join(resultsToSave))
# how to use the function
generate("1860-11")
Results for Script 1/2:
Result: Network Edges List usable for Gephi
Total of : 16,832 entries
freq = frequency of how many duplicated rows are in the dataset (1 = unique) id = counting places + counting articles plus issue date date = issue date of the article source = article + plus article count for each dispatch plus issue date target = place name tgn = tgn number that references to a geolocation
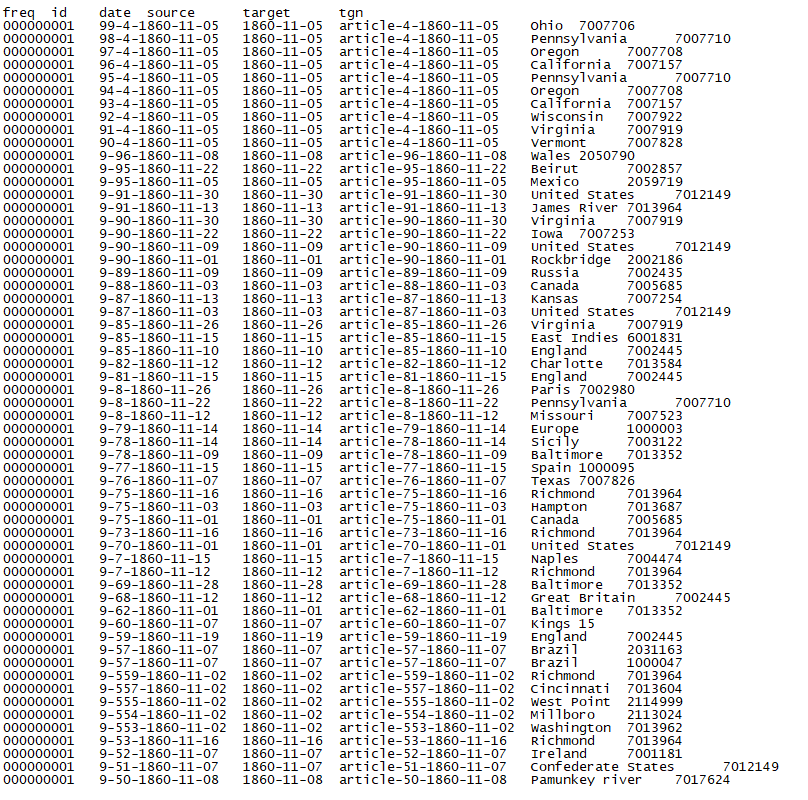
I tried to load the complete dispatch but the amount of results is to heavy for SNL. The second try was to load one year “1860” only but even this was too much for Gephi. The third try that worked was one month of a specific year. I choose November of 1860 “1860-11” and it worked. The network is still too complex but what appear to be little moons are the labels for articles for example that reference to a specific location. Basically Richmond is mentioned the most followed by others.
High zoom into the Richmond Node surrounded by all articles that reference to this place:
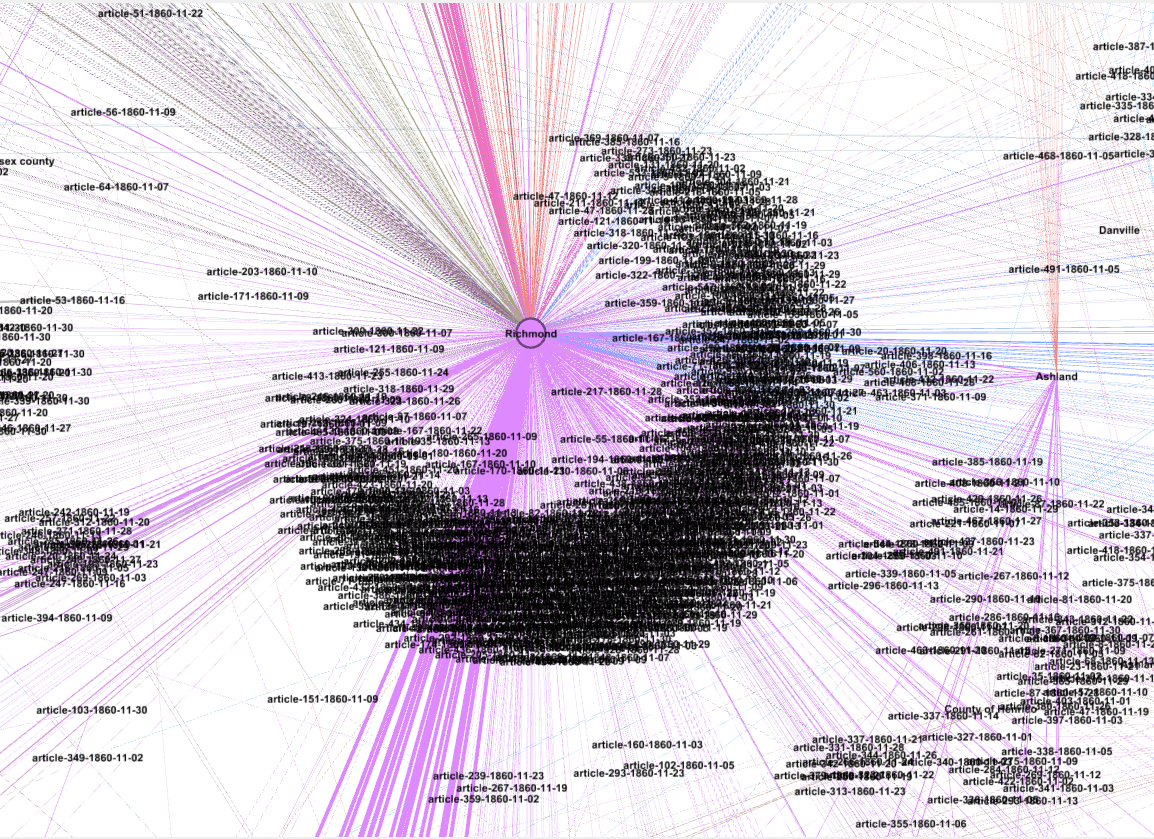
Medium Zoom of several nodes:

Other SNL network that used another script 2/2.
The script was not good enough since it did not produce unique IDs
Unique IDs are necessary for SNL or the double entries will be ignored. However, the network itself looked interessting. That is why I keep them online. The script for that is below.
Result: Network Edges List usable for Gephi
Total of : 47,429 entries
Important Note: The script above does not include place names that are mentioned once only.
I created an edges list that also includes place names mentioned once but the list is not workable for Gephi because the network gets to dense.
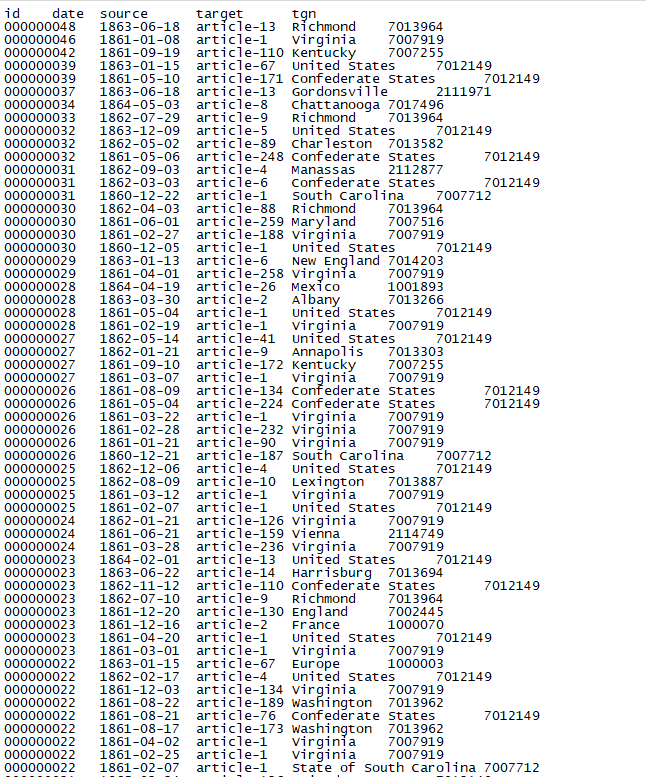
Gephi SNL Graphs
1:
Zoom into the connected network:
The cities that are connected the most to articles are: Richmond, Virginia, Washington, “Confederate States”, “United States”, “England”, North Carolina, …
The articles which are connected the most to cities are: article-99, article-9, article-96, article-97, …
Clusters: The above mentioned cities, states and articles also form various clusters. Richmond, Virginia and Whashington seem to be the most relevant.
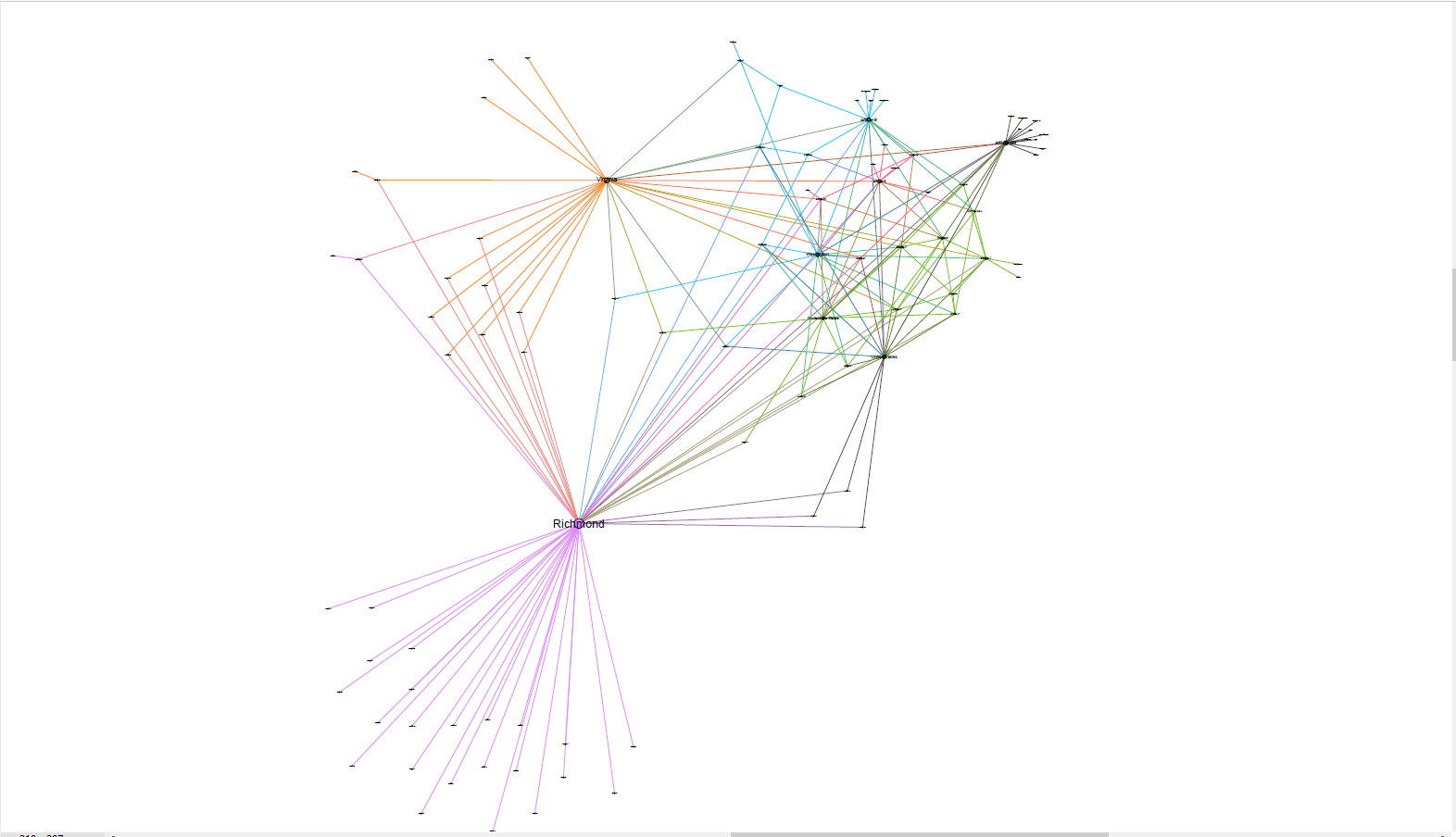
2:
The original picture without zoom shows thousands of cities, states and articles that are not connected at all according to Gephi.

Script 2/2: Not valid because it does not produce unique IDs
rom bs4 import BeautifulSoup
import re
import os
newPathToFolder = "----path to target folder to save files----"
pathToFolder = "----path to source folder with dispatch xml files----"
listOfFiles = os.listdir(pathToFolder)
dicFreq = {}
placeNames = []
resultsCSV = []
# for loop that opens all files of a defined folder and stores it with BeautifulSoup in variable soup
for f in listOfFiles:
soup = BeautifulSoup (open(pathToFolder+f, "r", encoding="utf8"), features="html.parser")
# searches for list items of "date" and return maximum two elemens
issue_date = soup.find_all("date", limit=2)[1] # only returns the second match
issue_date = issue_date.get("value")
# searches for all tags with "div3" and stores it in variable "articles"
articles = soup.find_all("div3", type = True)
# counter to count each article
counter = 0
for a in articles:
counter += 1 # for loop that counts each article
places = a.find_all("placename", key = True) # continues to find all placenames with an attribute
article = "article-" + str(counter) # variable that holds the issue date of the dispatch a string and an article counter
print(article)
for p in places:
place = p.get_text() # for loop to retrieve all placenames as value from the placename tag
key = p["key"].split(";") # variable that holds the tgn number
print(str(place) + "-" + str(key))
for k in key:
key = [d for d in k if d.isdigit()] # for loop to clean tgn numbers digits only
tag_id = ''.join(key)
placeList = "\t".join([issue_date,article,place,tag_id]) # creating a variable that holds each result article, place, tag_id
placeNames.append(placeList) # appending the variable to a list
for i in placeNames: # creating a frequency with a for loop for all place names
if i in dicFreq:
dicFreq[i] += 1
else:
dicFreq[i] = 1
for key, value in dicFreq.items(): # removes all placenames that are mention once only
if value > 1: # this will exclude items with frequency 1
newVal = "%09d\t%s" % (value, key)
# newVal will looks like: `000005486 TAB Richmond`
resultsCSV.append(newVal)
resultsCSV = sorted(resultsCSV, reverse=True) # sorting the results variable
print(len(resultsCSV)) # will print out the number of items in the list
resultsToSave = "\n".join(resultsCSV) # joining the results line by line
# creates a new file in a target folder with name + article counter + name + issue_date + txt file
newfile = newPathToFolder + "resultsFull_3.csv"
# creating a header for the final file
header = "id\tdate\tsource\ttarget\ttgn\n"
# saving
with open(newfile, "w", encoding="utf8") as f8:
f8.write(header+"".join(resultsToSave))