Code example to achieve the following tasks
This post relates to the data we collected from webscraping (see post webscraping of 8th May)
Task 1: Write a python script that will create clean copies of text from each issue of the “Dispatch” that you scraped before (make sure to keep the originals intact!).
import re
import os
newPathToFolder = "~/Documents/Dh_Tools/lesson7/4th/modified/"
pathToFolder = "~/Documents/Dh_Tools/lesson7/4th/"
listOfFiles = os.listdir(pathToFolder)
# ceates a for loop to open each file of a folder
for f in listOfFiles:
with open(pathToFolder+f, "r", encoding="utf8") as f1:
data = f1.read()
# removes all the xml markup from each file and stores it in a variable
text = re.sub("<[^<]+>","", data)
# creates a new file with modified.txt extention
newfile = pathToFolder+f + "_modified.txt"
# opens each files and writes the content stored in text
with open(newfile, "w", encoding="utf8") as f9:
f9.write(text)
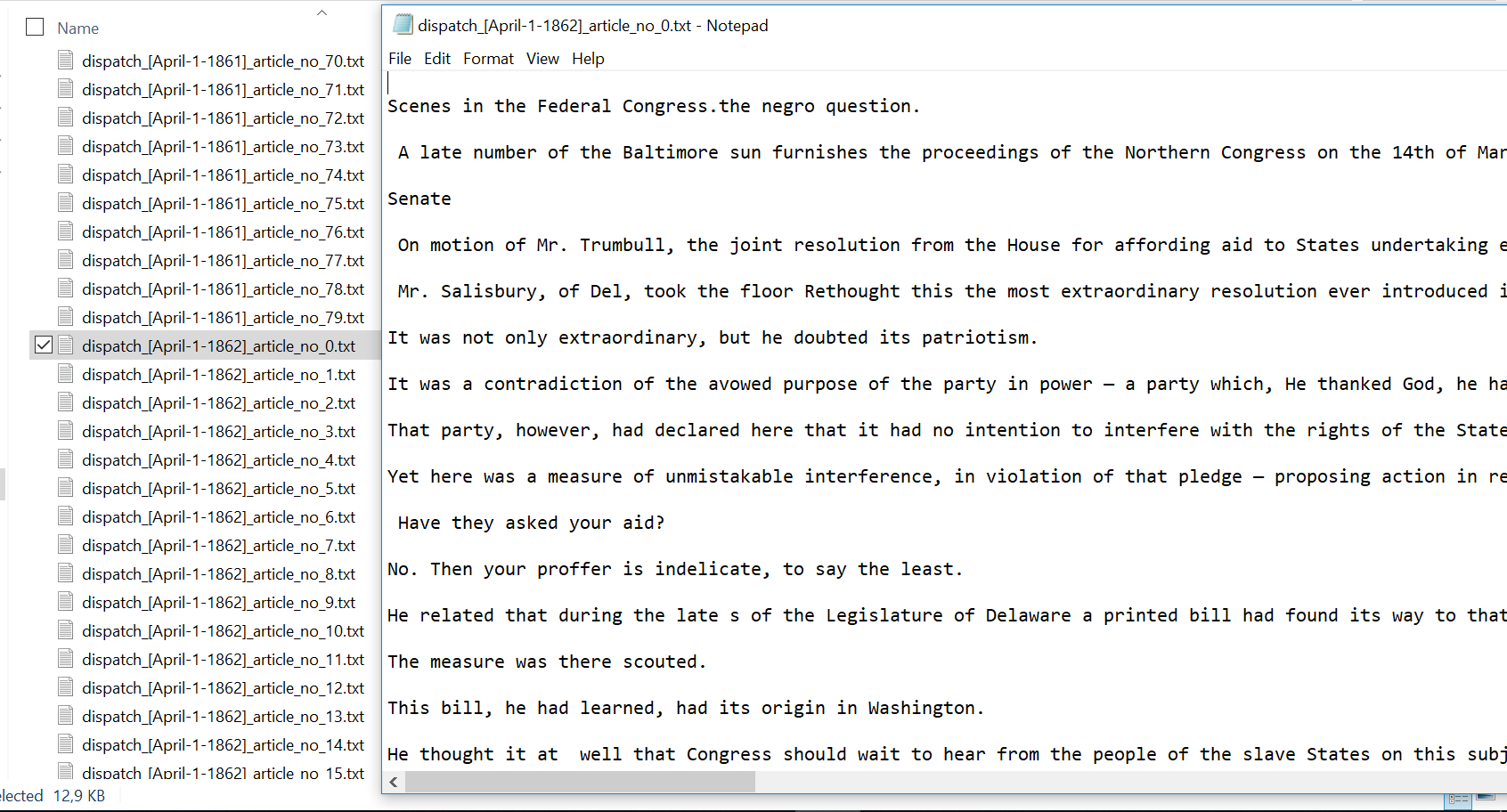
Result:
Except for setting a new target folder everything worked fine.
Task 2: Write a python script that will create clean copies of articles (!) from all issues of the “Dispatch”. (again, make sure to keep the originals intact!).
from bs4 import BeautifulSoup
import re
import os
newPathToFolder = "~/Documents/Dh_Tools/lesson8/articles_true/"
pathToFolder = "~/Documents/Dh_Tools/lesson7/4th/"
listOfFiles = os.listdir(pathToFolder)
# for loop that opens all files of a defined folder and stores it with BeautifulSoup in variable soup
for f in listOfFiles:
soup = BeautifulSoup (open(pathToFolder+f, "r", encoding="utf8"), features="html.parser")
# searches for list items of "date" and return maximum two elemens
issue_date = soup.find_all(["date"], limit=2)
# the next three searches simply clean out the result into month, day and year
issue_date = re.sub("<[^<]+>", "", str(issue_date))
issue_date = re.sub("\s,\s", "", str(issue_date))
issue_date = re.sub("\s", "-", str(issue_date))
issue_date = re.sub(",", "", str(issue_date))
# searches for all tags with type="article" and stores it in variable "articles"
articles = soup.find_all(type="article")
# for loop to count each articles with "a"
# automatically seperates all articles in "item"
for a, item in enumerate(articles):
# assiging the counter to a variable
counter = a
# cleaning all articles of xml tags
article = re.sub("<[^<]+>", "", str(item))
# creates a new file in a target folder with name + article counter + name + issue_date + txt file
newfile = newPathToFolder + "dispatch_" + str(issue_date) + "_article_no_" + str(counter) + ".txt"
# opens the newfile and writes each article into a sperate file
with open(newfile, "w", encoding="utf8") as f9:
f9.write(article)
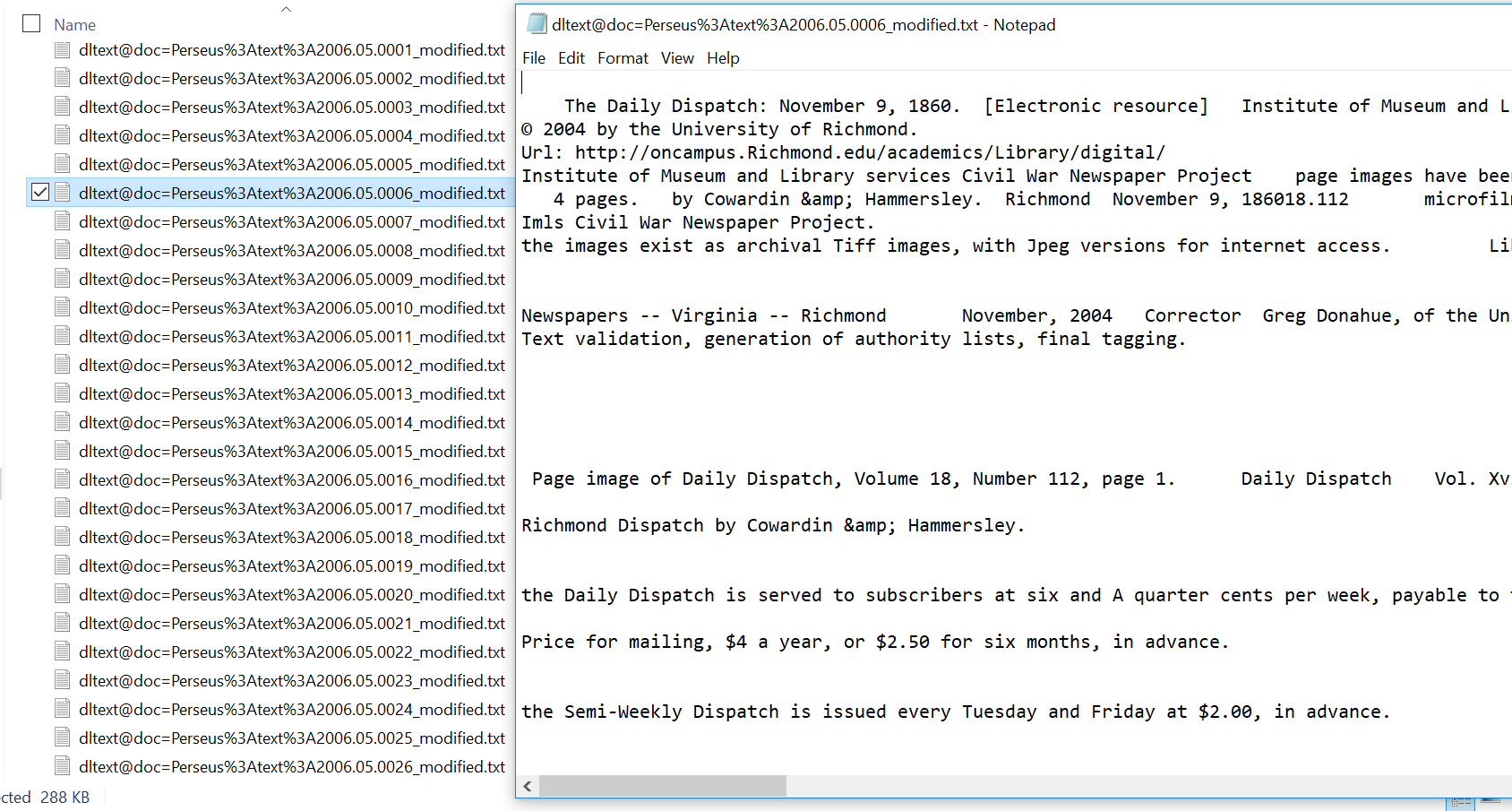
Result:
This is the closest I got so far. However, it seems that the search for “div3” does not find all articles. Finding issue dates and creating a counter seems to work fine however. The XML markup is removed nicely.
Updated version:
Since “div3” also returns empty files I am using “type=”article” as search criteria. The file ouput is much smaller and only 71,177 instead of 342,810. All files have text inside but I am still not 100% if each file represents one specific article. I also changed the date format a little bit.
- old search: articles = soup.find_all(“div3”)
- new search: articles = soup.find_all(type=”article”)
Updated version 2:
This final code example is now adapted to get the date much easier as well as accesses now div3 with type=article in one line of code. The result however stays the same as per output files like the previous update.
from bs4 import BeautifulSoup
import re
import os
newPathToFolder = "~/Documents/Dh_Tools/lesson8/articles_try_2/"
pathToFolder = "~/Documents/Dh_Tools/lesson7/4th/"
listOfFiles = os.listdir(pathToFolder)
# for loop that opens all files of a defined folder and stores it with BeautifulSoup in variable soup
for f in listOfFiles:
soup = BeautifulSoup (open(pathToFolder+f, "r", encoding="utf8"), features="html.parser")
# searches for list items of "date" and return maximum two elemens
issue_date = soup.find_all("date", limit=2)[1] # only returns the second match
issue_date = issue_date.get("value")
# searches for all tags with "div3" and stores it in variable "articles"
articles = soup.find_all("div3", {"type":"article"})
# for loop to count each articles with "a"
# automatically seperates all articles in "item"
for a, item in enumerate(articles[1:]): # with the latest part after articles the counter starts at 1 instead of 0
# assiging the counter to a variable
counter = a
# cleaning all articles of xml tags
article = re.sub("<[^<]+>", "", str(item))
# creates a new file in a target folder with name + article counter + name + issue_date + txt file
newfile = newPathToFolder + "dispatch_" + str(issue_date) + "_article_no_" + str(counter) + ".txt"
# opens the newfile and writes each article into a sperate file
with open(newfile, "w", encoding="utf8") as f9:
f9.write(article)